-
Hey, guest user. Hope you're enjoying NeoGAF! Have you considered registering for an account? Come join us and add your take to the daily discourse.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Recent PS4 SDK update unlocked 7th CPU core for gaming
- Thread starter DieH@rd
- Start date
Wtf are people talking about? Afaik the SPEs are simply not capable to run a full OS for the simple reason that the "Orchestra conductor" that assigns tasks to them is the PPE. SPEs are incapable of assigning themselves tasks, or assigning tasks to each other directly...
At least i understood your first sentence.
How did i even end up here, i feel like penny.
serversurfer
Member
Finally had a chance to sit down and watch this.They have a really cool technical talk here (one hour long): http://www.gdcvault.com/play/1022186/Parallelizing-the-Naughty-Dog-Engine
Stuff I learned:
Fiber switching is really fast.
I had assumed they'd have a worker thread dedicated to each game system; an AI thread, physics thread, etc. Instead, they just have a generic worker thread running on each CPU core, and those threads all execute fibers as they become available. When a worker thread completes a fiber's current job, it just grabs another fiber to process. It doesn't matter if it contains an AI job or a physics job or what. It's a job that needs to get done, and this worker thread isn't doing anything, so it does it. All six of the worker threads just constantly process whatever ready fiber they can find. This is better than dedicating a thread/core to each subsystem, because it allows you to process six AI jobs simultaneously, or zero, instead of only one at a time.
This also means that ND's engine should benefit fairly linearly from the unlocking of Core6. Because their worker threads aren't particular about what type of job they're executing, their engine's job throughput should increase nearly 17% assuming it is indeed a 100% unlock because they don't have very many synchronization points in their engine. He said the engine is more like an OS, and that's how I've kind of pictured "modern" game engine; primarily a collection of daemons that perform very specific tasks very efficiently, and are capable of performing their job without worrying too much about what its fellow daemons are up to.
They use something called atomic counters for synchronization. It's basically a global unsigned int. If a job is processing some data that another job will depend on, it sets this counter to some non-zero value. The dependent job can then be dispatched immediately, and it tests if the counter has reached 0 yet. If not, the job's fiber is just slept, and the worker thread simply switches context to a fiber that isn't blocked. The slept fiber is added to a list of fibers waiting on that particular counter, and when it reaches zero, all of the waiting jobs are flagged as ready to go for the next available worker thread.
This is especially useful because their job system is cooperative rather than preemptive. There's no way to interrupt a running job, so if it gets stuck waiting on a value from another job, it's completely stuck. To test whether an operation is safe to perform, the job calls WaitForCounter(counter, value), and if the counter doesn't contain the requested value, the fiber puts itself to sleep, relinquishing control of the thread so another fiber can execute.
While they don't lock particular subsystems to specific cores, they do lock specific worker threads to specific cores. Because they mostly have the CPU cores to themselves, their worker threads can run for many, many cycles without interruption. But, it's a Unix system, and the kernel is king, so occasionally it will come by and boot one of the threads off of its preferred core for a moment. So in that time when the worker thread has nowhere to execute, it complains, and all of the other worker threads offer up their cores, seeing as how they've been "hogging it" for the last however many cycles. The net result of this that every time they had a kernel-forced context switch, is actually triggered six (or more!) switches, as their worker threads all played musical cores. So they use affinity to bind worker0 to Core0, and if it gets booted, it simply waits for the core to become available again rather than interrupting the other worker threads. This exposes another advantage of generic workers; if one gets blocked by the kernel, you simply process jobs
To improve CPU utilization, they changed the way they thought of frames. They boiled the definition of a frame down to, "A piece of data that is processes and ultimately displayed on the screen." This data goes through three phases of life.
Game Logic: This is where all of your dice-rolling and bookkeeping happens. You run your AI and physics routines, process hit detection, update hit points All of that good stuff. Basically, you're determining the current state of the world.
Render: After you've done your world simulation to determine the state of the environment, this is where you start describing the scene for the GPU to draw. Draw calls and such go here. There's a bunch, especially if the scene is complicated.
GPU: This last phase doesn't have anything to do with the CPU at all. Once all of the draw calls have been dispatched to the GPU, the CPU's involvement with that frame pretty much ends, and it can get started on the next frame.
So at 60 fps, the CPU basically has 16.67 ms to complete the game logic and rendering phases, or the frame won't be ready in time for the GPU to do its thing. Problem was, they had about 100 ms worth of code to execute, and even spread across six cores, it still took about 25 ms to get from the start of game logic to the end of rendering. They weren't getting very good utilization on the CPU; a lot of the silicon was sitting idle a lot of the time.

So the solution was to run the game logic and rendering phases simultaneously, and eliminate dependencies by sending the frame through each phase sequentially.

This eliminates all contention between the Game and Render phases, because they're always working on completely different frames. If a core is available, it can always be executing a rendering job, because all of the data the render requires was completed in the previous beat of our 16.67 ms "phase clock." By making the two phases completely asynchronous, they were able to vastly improve their utilization and get their overall execution time to a svelte 15.5 ms.

Stuff I suspect:
Thanks to heterogeneous queueing, things should run fairly similarly from the GPU's perspective. Any job destined for the CPU gets added to one of the CPU job queues, where it's picked up by the next available fiber and executed by the next available worker. Any jobs tagged for the GPU whether compute or traditional rendering should be handled similarly, but by a system completely independent from the system that feeds the CPU.
So if the GPU is being fed similarly, would it also be a good idea to do your compute and render out-of-phase on the GPU, so it's doing all of its rendering for frame1 while simultaneously doing the compute needed for frame 2? Or do we need to move things even further out of phase, so Game on the CPU never stalls waiting for Compute to be ready on the GPU?
Stuff that confused me:

Okay, tagged data. I understand how it works and why it's good. It's okay if new memory for a fiber is allocated by a different thread, because it all goes through to the same backing store, since all of the threads have a Game block in the allocator, right? But what happens if the worker thread picks up a Render fiber, which it's equally likely to do ay any given time, yes? Is a Render block automagically loaded in to the allocator when a Render fiber is picked up? Is that any more expensive than a normal fiber switch?
Fibers provide context, but how, exactly? When he described the queueing system, it sounded like the top job from the highest-priority queue was simply popped by the next available fiber. Is that correct? If so, where does the "context" come from, or is it not that kind of context? It seems like a random sequence of jobs would be moving through any given fiber; not really grouped by dependency or anything like that. So is "context" simply making sure the job is working with the correct memory location, or is there some greater context like, "Do these things in this order" happening? Is a fiber a reusable, one-shot wrapper to "target" a job, or does it provide some sort of job-to-job context as well?
FakeEdit: Okay, I can imagine a sequence of commands that can be executed atomically, but are still only useful when performed in a specific order. So does a fiber tie that specific sequence of jobs together? How, if they're just pulling jobs from the queue, one at a time?
surfer's tl;dr:
ND's engine is pretty fucking sweet. It seems as scalable as it is flexible, and assuming a 100% unlock of the seventh core I wouldn't be surprised if they saw a 15% boost in CPU performance with just a few lines of code to set up a seventh worker.
real tl;dr:
"Very helpful."
LordOfChaos
Member
Sure 7 Jaguar cores is good enough in a console when a lot of work can be offloaded to the GPGPU but why would you minus the Cell's SPUs to say it wasn't so great?
But the Ubi slides demonstrate exactly what he said it was good at. Lots of relatively simple, but highly repetitive parallel math, like physics? Excellent (for the time, trumped by the lowliest GPUs now). Lots of branching paths, as in AI, pathfinding, etc? Takes some doin'. You can even do that on GPUs now, but it's pretty convoluted, and I don't think very efficient.
It's almost like Cell was good at Single Instruction, Multiple Data, we should make a short acronym for that or something

Because a Pentium 4* from 2004 was able to beat it in most benchmarks (minus the SIMD/flops benchmarks, of course).
* Mind you, NetBurst wasn't exactly the most efficient x86 microarchitecture.
SIMD is not suitable for everything as you think it is. It's like having a super-smart kid who is really good at maths (linear algebra/matrix multiplication), but pretty much dumb at everything else (history, biology, literature etc.) That's what the Cell SPU/GPGPU is. It excels in one field, but it's useless in everything else.
I don't think SIMD is suitable for everything but I know that a HSA APU can do a lot with it's GPGPU like pathfinding to help with AI. better AI in racing games & games like Grand Theft Auto can have bigger crowds walking around & so on.

LordOfChaos
Member
I don't think SIMD is suitable for everything but I know that a HSA APU can do a lot with it's GPGPU like pathfinding to help with AI. better AI in racing games & games like Grand Theft Auto can have bigger crowds walking around & so on.
Bear in mind this is a new paradigm even in 2015; we're talking about the 2006 Cell here, a decade ago. Hard to say if new APIs and modern compute-bolstered GPU architectures could have been approximated on the Cells SPUs in terms of trying to do AI/pathfinding on them. If it could have been, there would be more load on the developer and less support structure.
I don't think anyone really did try, AI is far from the largest chunk of CPU time as is.
Besides, much of it's late life performance realization was squandered on making up for the RSX with multiple SPUs doing vertex and culling work for it.
Dictator93
Member
I don't think SIMD is suitable for everything but I know that a HSA APU can do a lot with it's GPGPU like pathfinding to help with AI. better AI in racing games & games like Grand Theft Auto can have bigger crowds walking around & so on.
Pretty sure this is referring to mixed computing in the PC space with an AMD APU and a dedicated GPU as well.
Negotiator
Member
These buzzwords are cool and all, but I'm not sure if you fully understand them (it requires a bit of programming background) or if you just copy/paste them from articles.I don't think SIMD is suitable for everything but I know that a HSA APU can do a lot with it's GPGPU like pathfinding to help with AI. better AI in racing games & games like Grand Theft Auto can have bigger crowds walking around & so on.
HSA/hUMA basically means that the CPU and the GPU have access to a unified memory pool/common address space (they can use the same pointers) and work on common sets of data. In layman's terms, this means that a console can do more with less memory. That's why you see PC ports like Batman suffering and needing exorbitant amounts of RAM, while a console can run the same game with less than half the RAM (last I checked they had 5GB for games). This game was programmed with consoles' unified memory in mind.
Here's a more detailed explanation: http://www.redgamingtech.com/amd-huma-ps4-and-xbox-one-memory-system-analysis/
In the long term, it also means that CPUs will have to abandon their crufty legacy (I'm talking about the FPU/SIMD circuitry <-- those transistors can be better spent somewhere else), since GPGPU is a far more efficient programming model to run SIMD code.
Regarding 3rd party developers, I don't think that many of them use GPGPU. DICE has done some pretty good job with Frostbite 3, but what about the rest of the industry?
I'm pretty sure that most devs still use high-level APIs (libGNMX/DX11) for console games. That's why we see games like Just Cause 3 dropping to 20fps. It would be a real shame if they used the CPU for physics, since Jaguar is clearly not fit for that job (AVX vector units are not as powerful as GCN vector units).
jellies_two
Member
surfer's tl;dr:
ND's engine is pretty fucking sweet. It seems as scalable as it is flexible, and assuming a 100% unlock of the seventh core I wouldn't be surprised if they saw a 15% boost in CPU performance with just a few lines of code to set up a seventh worker.
real tl;dr:
"Very helpful."
Did you catch whether they offloaded anything to gpu compute? I got the sense no. They took all the PS3 spu and cpu jobs and squashed them onto 6 cores smooshing two frames of work together in order to better utilise the cores, while the gpu appeared to be hardly breathing.. All their effort was concentrated in generating the draw lists first faster than 30 then faster than 60..
It seemed like a tough battle and surprisingly even though they were only doubling speed and increasing resolution of a working PS3 game, they also had to battle to keep memory usage from running away despite having approx 50 billion times more bytes of memory vs PS3 ...
Bear in mind this is a new paradigm even in 2015; we're talking about the 2006 Cell here, a decade ago. Hard to say if new APIs and modern compute-bolstered GPU architectures could have been approximated on the Cells SPUs in terms of trying to do AI/pathfinding on them. If it could have been, there would be more load on the developer and less support structure.
I don't think anyone really did try, AI is far from the largest chunk of CPU time as is.
Besides, much of it's late life performance realization was squandered on making up for the RSX with multiple SPUs doing vertex and culling work for it.
"One of our first goals when we started Uncharted: Drake's Fortune was to push what's been done in animation for video games. We developed a brand new animation system that took full advantage of the SPU's. Nathan Drake's final animation is made of different layers like running, breathing, reloading weapons, shooting, facial expression, etc; we end up decompressing and blending up to 30 animations every frame on the SPU's."
"The main thing about the PlayStation 3 is the Cell processor and more specifically the SPU's. We are only using 30 percent of the power of the SPU's in Uncharted. We've been architecting a lot of our systems around this and we were able to take full advantage of that power. A big part of our systems is running on SPU's: scene bucketing, particles, physics, collision, animation, water simulation, mesh processing, path finding, etc. For our engine, the cool thing about having the SPU's is the fact we can minimize what we send to the RSX (the graphic chip), it allows us to reject unnecessary information and get the RSX to be very efficient. "
"We are constantly streaming animations, level data, textures, music and sounds. It would have been impossible to get this amount of data at that speed to memory without the hard drive. And of course on top of that we use the SPU's to decompress all this data on the fly."
Panajev2001a
GAF's Pleasant Genius
These buzzwords are cool and all, but I'm not sure if you fully understand them (it requires a bit of programming background) or if you just copy/paste them from articles.
HSA/hUMA basically means that the CPU and the GPU have access to a unified memory pool/common address space (they can use the same pointers) and work on common sets of data. In layman's terms, this means that a console can do more with less memory. That's why you see PC ports like Batman suffering and needing exorbitant amounts of RAM, while a console can run the same game with less than half the RAM (last I checked they had 5GB for games). This game was programmed with consoles' unified memory in mind.
Here's a more detailed explanation: http://www.redgamingtech.com/amd-huma-ps4-and-xbox-one-memory-system-analysis/
In the long term, it also means that CPUs will have to abandon their crufty legacy (I'm talking about the FPU/SIMD circuitry <-- those transistors can be better spent somewhere else), since GPGPU is a far more efficient programming model to run SIMD code.
Regarding 3rd party developers, I don't think that many of them use GPGPU. DICE has done some pretty good job with Frostbite 3, but what about the rest of the industry?
I'm pretty sure that most devs still use high-level APIs (libGNMX/DX11) for console games. That's why we see games like Just Cause 3 dropping to 20fps. It would be a real shame if they used the CPU for physics, since Jaguar is clearly not fit for that job (AVX vector units are not as powerful as GCN vector units).
Unified memory like the Xbox 360 has brings versatility and less duplication of data, but the additional win brought by unified address spaces is that you can avoid bandwidth and storage wise wasteful in memory move operations to share data across CPU and GPU.
Negotiator
Member
XBOX360 is more versatile than the PS3, but it does not have a unified address space, so duplication of work sets is unavoidable:Unified memory like the Xbox 360 has brings versatility and less duplication of data, but the additional win brought by unified address spaces is that you can avoid bandwidth and storage wise wasteful in memory move operations to share data across CPU and GPU.

http://www.redgamingtech.com/amd-huma-ps4-and-xbox-one-memory-system-analysis/
These buzzwords are cool and all, but I'm not sure if you fully understand them (it requires a bit of programming background) or if you just copy/paste them from articles.
HSA/hUMA basically means that the CPU and the GPU have access to a unified memory pool/common address space (they can use the same pointers) and work on common sets of data. In layman's terms, this means that a console can do more with less memory. That's why you see PC ports like Batman suffering and needing exorbitant amounts of RAM, while a console can run the same game with less than half the RAM (last I checked they had 5GB for games). This game was programmed with consoles' unified memory in mind.
Here's a more detailed explanation: http://www.redgamingtech.com/amd-huma-ps4-and-xbox-one-memory-system-analysis/
In the long term, it also means that CPUs will have to abandon their crufty legacy (I'm talking about the FPU/SIMD circuitry <-- those transistors can be better spent somewhere else), since GPGPU is a far more efficient programming model to run SIMD code.
Regarding 3rd party developers, I don't think that many of them use GPGPU. DICE has done some pretty good job with Frostbite 3, but what about the rest of the industry?
I'm pretty sure that most devs still use high-level APIs (libGNMX/DX11) for console games. That's why we see games like Just Cause 3 dropping to 20fps. It would be a real shame if they used the CPU for physics, since Jaguar is clearly not fit for that job (AVX vector units are not as powerful as GCN vector units).
I understand everything that I said
But we should probably move the GPGPU talk here
I miss Cerny.. Anybody knows what he is up to these days?
He started to play MGS5 recently according to my activity feed on PS4
Panajev2001a
GAF's Pleasant Genius
XBOX360 is more versatile than the PS3, but it does not have a unified address space, so duplication of work sets is unavoidable:
http://www.redgamingtech.com/amd-huma-ps4-and-xbox-one-memory-system-analysis/
PS3 traded versatility for somewhat more bandwidth to the CPU and some extra to the GPU too (who can read at decent speed from both pools) and was puzzling saddled with a cut down FlexIO bus between CPU and GPU which gave horrible bandwidth to the VRAM when accessed from the CPU side thus unbalancing the design a bit and adding another layer of complexity to using SPU's to assist the GPU.
We were already agreeing that the Xbox 360 duplicated data and wasted bandwidth due to lacking a unified address space, but I would argue that on PS3 you would have wasted even more due to double or quad buffering data being sent back and forth across the bus (like you would on the good ol' VU1's micro memory).
LordOfChaos
Member
I mean any human developers though
I should learn not to bet against Naughty Dog
Like I said though, like GPU based AI, it's possible but more tricky. I'm getting fuzzy on what our original points were. I think it still stands that the SPUs were great at SIMD to the sacrifice of everything else, a single developer with a lot of funding with something to prove from Sony being able to move pathfinding to the SPU doesn't mean they're /great/ at it, but capable.
serversurfer
Member
Didn't Ubi say that like half their CPU time was going to AI in ACI don't think anyone really did try, AI is far from the largest chunk of CPU time as is.
arity?The ramifications of a split pool go beyond the need for more chips to hold the duplicated data. The latency associated with transferring data between the two pools makes the system considerably less performant. A short operation that transferring to the GPU would make for an easy win on a hUMA system may end up being a huge loss on a conventional system by the time all of the inter-chip communication transpires.HSA/hUMA basically means that the CPU and the GPU have access to a unified memory pool/common address space (they can use the same pointers) and work on common sets of data. In layman's terms, this means that a console can do more with less memory. That's why you see PC ports like Batman suffering and needing exorbitant amounts of RAM, while a console can run the same game with less than half the RAM (last I checked they had 5GB for games). This game was programmed with consoles' unified memory in mind.
"Most slackers won't even bother, so why should we care?" =/Regarding 3rd party developers, I don't think that many of them use GPGPU. DICE has done some pretty good job with Frostbite 3, but what about the rest of the industry?
It wasn't mentioned at all, but I got the impression that anything happening on the GPU was a matter for another talk. The only time they mentioned the GPU at all was to say it was responsible for the final phase of frame preparation. You assume work previously being done on the SPU is now being done on the CPU, but I don't recall him saying that either. I would assume that most or all SPU work would be well suited for transfer to the GPU, and there'd likely be a bunch of additional operations now suitable for transfer thanks to the new architecture.Did you catch whether they offloaded anything to gpu compute? I got the sense no. They took all the PS3 spu and cpu jobs and squashed them onto 6 cores smooshing two frames of work together in order to better utilise the cores, while the gpu appeared to be hardly breathing.. All their effort was concentrated in generating the draw lists first faster than 30 then faster than 60..
It seemed like a tough battle and surprisingly even though they were only doubling speed and increasing resolution of a working PS3 game, they also had to battle to keep memory usage from running away despite having approx 50 billion times more bytes of memory vs PS3 ...
But again, that process would be largely irrelevant to the subject of his talk. I would say it's very likely that tons of work is being done by the GPU, but his talk began with "whatever was left for the CPU at that point," because managing what's happening on the CPU was the subject of the talk. Like I said, I strongly suspect that the GPU is fed in much the same fashion as the CPU, but it'd be nice to get some confirmation of that from someone who actually knows what they're talking about. lol
If it works like I think, divvying up the work should actually be quite easy for the devs. The PS4's compiler can take any job and produce a version that will run on either chip, and devs simply choose the more performant option. As such, I imagine that once compiled, their engine is basically distilled in to a collection of jobs to be run on the CPU and another collection to run on the GPU, and each collection is just automatically fed in to their respective queues for execution.
MillionStabs
Banned

vpance
Member
He started to play MGS5 recently according to my activity feed on PS4
Only proper to play the new hire's latest game before he comes on board
serversurfer
Member
It's really not that tricky, but "GPU-based AI" is a bit of a misnomer. It would be more accurate to call it "GPU-augmented AI." Basically, there are some vital operations in AI like pathfinding that the CPU can perform, but very, very slowly. The GPU is really fast at that stuff, but not so good at the rest. So basically, you compile your AI routines such that any decision making occurs on the CPU, and all of the pathfinding is handled by the GPU. When the CPU needs access to the path data, it just accesses the variable that the GPU wrote out, because they share all of their data automatically.Like I said though, like GPU based AI, it's possible but more tricky.
LordOfChaos
Member
I was digging through some of the original Cell documents - heh, remember when Intel was going to do this by 2015?
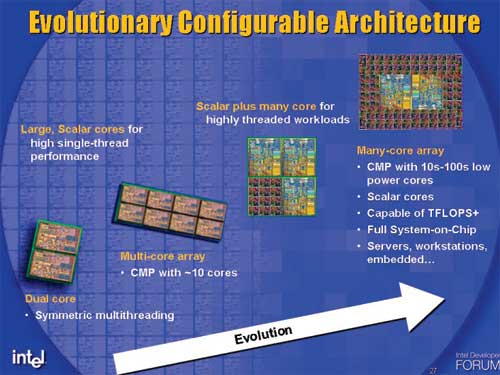
I guess they somewhat ended up there with a GPU strapped to every CPU, but not quite the Cell-like helper core they envisioned with Tflop+ CPUs by now.
I guess they somewhat ended up there with a GPU strapped to every CPU, but not quite the Cell-like helper core they envisioned with Tflop+ CPUs by now.
I was digging through some of the original Cell documents - heh, remember when Intel was going to do this by 2015?
I guess they somewhat ended up there with a GPU strapped to every CPU, but not quite the Cell-like helper core they envisioned with Tflop+ CPUs by now.
http://www.pcworld.com/article/3005...ore-supercomputing-chip-into-workstation.html

https://www.nersc.gov/assets/Uploads/KNL-ISC-2015-Workshop-Keynote.pdf
LordOfChaos
Member
Similar concept, but I think Intel envisioned having this in every consumer CPU by now, back in 2005, rather than Knights Landing which is a card for high performance compute clusters. It's also not Intels traditional big cores surrounded by smaller helper cores; it's small, iirc P3-like x86 cores, through and through.
Similar concept, but I think Intel envisioned having this in every consumer CPU by now, back in 2005, rather than Knights Landing which is a card for high performance compute clusters. It's also not Intels traditional big cores surrounded by smaller helper cores; it's small, iirc P3-like x86 cores, through and through.
It says servers & workstations in the picture you posted.