No, I'd like to continue, because I think you're scared of your rhetoric getting blown open. Welp, my C4s are already placed and I'm about to detonate.
Reducing RAM bandwidth to a percentage is a ridiculous way to compare bandwidths, because you're doing it from a reductive POV. Operations like RT and higher-resolution asset feeding to the GPU rely heavily on bandwidth. The AMD cards are only competing with Nvidia's in terms of traditional rasterization performance, and it's arguable if the narrower GDDR6 bandwidth helps or hurts; you always have to keep in mind RDNA 2 cards have more RAM capacity than the Nvidia cards, in some cases almost 2x more memory capacity, and that's almost as important as the actual bandwidth.
You do realize that features of Series X's I/O, like DirectStorage, are not yet deployed widely on PC, right? DirectStorage is a restructuring of the filesystem as a whole, it's not just a means of getting more realized bandwidth from NVMe SSD drives. Other features of the system tied to the I/O but not necessarily in the I/O (like SFS) have no equivalents in hardware on PC. So again, you're completely incorrect on that one as well. There hasn't been confirmation if the RDNA 2 GPUs have cache scrubbers; IC as it's known so far is just a fat 128 MB L3$ embedded on the GPU. Very similar to the eSRAM the XBO had; they were both for framebuffers. IC is enough for 4x 4K framebuffers or 1x 8K framebuffer, and we don't exactly know what the bandwidth or latency of IC is either.
Seeing that, again, in only rasterization performance, AMD RDNA 2 equivalents can keep up with the new Nvidia cards then we can assume both bandwidth and latency on IC is quite good. You don't actually need cache scrubbers for a L3$, but we can throw a bone and say that RDNA 2 GPUs might have that. The point is all of this is only benefiting AMD on rasterized performance; anything that can leverage RT or DLSS image upscaling techniques, AMD loses out on massively. That's because things like RT benefit from bandwidth, capacity AND the actual hardware acceleration in the GPU; IC only helps with one,
maybe two of those, but you need all three.
As for what inspired IC, I'm sure Sony may've had some influence but a fat L3$/L4$ is nothing new in system designs, at all. Again, MS did this with the 32 MB embedded eSRAM for XBO, but Intel also did this with embedded eSRAM (maybe eDRAM?) cache on some of their CPUs from the early 2010s'. AMD just took an age-old idea and put their own spin on it, I can guarantee you they weren't simply looking at what Sony was doing and you'd have to verify the RDNA 2 PC cards have cache scrubbers to accredit this to Sony actually.
You've been going all over the place with what you think you're talking about, because you don't understand how bus contention works (seemingly) nor do you seem to understand that you cannot aggregate access to the fast and slow pools as an average because that doesn't reflect how the two pools will be used in practice. We should also assume that if effective bandwidth from fast & slow pool access would drop to a level even near PS5's peak bandwidth, let alone lower than that, then Microsoft would have clearly taken the hit and gone with 20 GB. It's not like they're a team of gasping seals that just learned about electronics yesterday

The amount of willing ignorance and disinformation surrounding Hitman 3 not being a native port on PS5 going on in the thread is astounding.
I bet someone is probably calling me a Microsoft fanboy as we speak, even though I was just pointing out technical deficiencies in The Medium yesterday

.

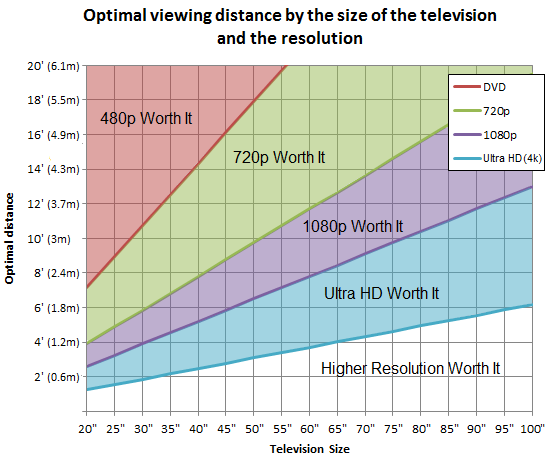
 That’s the only reason for all these pages. But keep doing the great work.
That’s the only reason for all these pages. But keep doing the great work.



